An experiment in open science: exoplanet population inference
The source for this post can be found here. Please open an issue or pull request on that repository if you have questions, comments, or suggestions.
Warning this is an extremely technical blog post (even for me) but I think that it’s an interesting experiment so I thought I would post it anyways!
The Kepler Mission has been a great success story for open science. The recent data releases have been on a fast and regular schedule and the data products are sometimes made public before the science office publishes their papers. Therefore, when the most recent installment in the “rate of Earths” saga—a discussion close to my heart—hit the ArXiv as Burke et al. (2015), I decided to see if I could reproduce their results by following the steps described in their paper. Crazy, right?
In this blog post, I’ll go through the steps to reproduce most of their key results as an experiment in Open Science. [Spoiler alert: I dont get exactly the same results but I do come to the same conclusions…]
It’s also worth noting that Burke also posted code and results to supplement the paper: christopherburke/KeplerPORTs.
The science case#
While the point of this post isn’t to discuss the physical implications of this result, it is worth taking a moment to motivate this experiment. One of the key areas of research in exoplanets is (what I like to call) population inference; determining the underlying occurrence rate and distribution of exoplanets and their physical properties. This is interesting as a data science problem because we now have large catalogs of exoplanet discoveries and characterizations and it’s interesting scientifically because it is the best shot we have of connecting exoplanet observations to theories of the formation and evolution of exoplanet systems. It also places a constraint on the frequency of planets like Earth and planetary systems like our Solar system (Are we alone? and all that…).
There has been a huge amount of research in this field but Burke et al. (2015) present (arguably) the most careful treatment of the systematic effects based on a characterization of the official Kepler pipeline. Even before submission, the data products describing this characterization were all publicly available on the Exoplanet Archive.
The problem#
The basic data analysis question that we’re trying to answer here is: given an incomplete catalog of planet parameters (smaller planets on longer periods are harder to find), what can we say about the underlying distribution of properties? For this model, we’ll use the Poisson process likelihood to compute the probability of a set of measurements (e.g. orbital period, planet radius, etc.) $w_k = (P_k,\,R_k)$, given a parametric model for the underlying “occurrence rate” $\Gamma_\theta(w)$
where $Q(w)$ is an estimate of the (mean) detection efficiency (or completeness) as a function of the parameters $w$. Then, we just need to optimize for $\theta$ or choose a prior $p(\theta)$ and sample using MCMC. Like Burke et al., we’ll build our model in orbital period (in days) and planet radius (in Earth radii) and use a product of independent power laws in the two dimensions for $\Gamma_\theta (w) = \Gamma_\theta (P)\,\Gamma_\theta (R)$.
The data#
To start, let’s download (and cache) the dataset from the Exoplanet Archive. Don’t worry about the details of these functions but what they do is download the csv tables (q1_q16_stellar and q1_q16_koi) and save them as a pandas block.
Edit: for the purposes of reproducibility I’ve saved the pre-generated tables to Zenodo and we’ll download those first. But, the code used to create these data files is still included below if you don’t want to use the pre-generated files.
!mkdir -p data
!wget -qO data/q1_q16_koi.h5 "https://zenodo.org/record/6615440/files/q1_q16_koi.h5?download=1"
!wget -qO data/q1_q16_stellar.h5 "https://zenodo.org/record/6615440/files/q1_q16_stellar.h5?download=1"
import os
import requests
import pandas as pd
from io import BytesIO
def get_catalog(name, basepath="data", columns="*"):
fn = os.path.join(basepath, "{0}.h5".format(name))
if os.path.exists(fn):
print("Using cached data file.")
return pd.read_hdf(fn, name)
if not os.path.exists(basepath):
os.makedirs(basepath)
print("Downloading {0}...".format(name))
url = (
"http://exoplanetarchive.ipac.caltech.edu/cgi-bin/nstedAPI/"
"nph-nstedAPI?table={0}&select={1}"
).format(name, columns)
r = requests.get(url)
if r.status_code != requests.codes.ok:
r.raise_for_status()
fh = BytesIO(r.content)
df = pd.read_csv(fh)
df.to_hdf(fn, name, format="t")
return df
Now we will make the cuts on the stellar sample to select the G and K dwarfs:
$4200\,K \le T_\mathrm{eff} \le 6100\,K$,$R_\star \le 1.15\,R_\odot$,$T_\mathrm{obs} > 2\,\mathrm{yr}$,$f_\mathrm{duty} > 0.6$, and$\mathrm{robCDPP7.5} \le 1000\,\mathrm{ppm}$.
import numpy as np
thresh = [1.5, 2.0, 2.5, 3.0, 3.5, 4.5, 5.0, 6.0, 7.5, 9.0, 10.5, 12.0, 12.5, 15.0]
cols = [
"mesthres{0:02.0f}p{1:.0f}".format(np.floor(t), 10 * (t - np.floor(t)))
for t in thresh
]
stlr = get_catalog(
"q1_q16_stellar",
columns="kepid,teff,logg,radius,mass,dataspan,dutycycle,rrmscdpp07p5,"
+ ",".join(cols),
)
# Select G and K dwarfs.
m = (4200 <= stlr.teff) & (stlr.teff <= 6100)
m &= stlr.radius <= 1.15
# Only include stars with sufficient data coverage.
m &= stlr.dataspan > 365.25 * 2.0
m &= stlr.dutycycle > 0.6
m &= stlr.rrmscdpp07p5 <= 1000.0
# Only select stars with mass estimates.
m &= np.isfinite(stlr.mass)
base_stlr = pd.DataFrame(stlr)
stlr = pd.DataFrame(stlr[m])
print("Selected {0} targets after cuts".format(len(stlr)))
Using cached data file.
Selected 91446 targets after cuts
After applying these same cuts to a pre-release version of this catalog, Burke et al. found 91,567 targets.
[Using the machine readable version of their Table 1, I tried to work out the reason for this difference and I couldn’t reverse engineer any cause. Some of the targets missing from our catalog are just artificially fixed at Solar values so they seem reasonable to skip. This effect explains about half the difference between the results.]
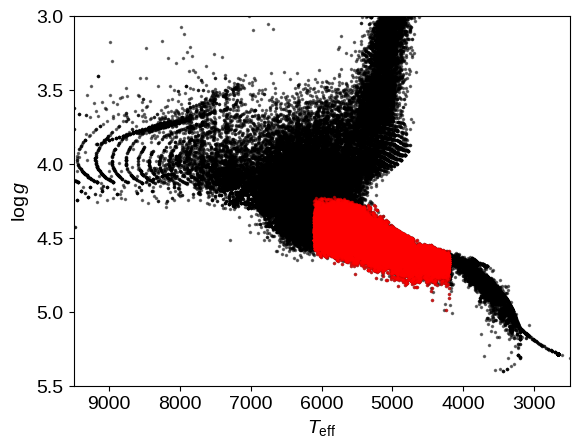
We can now make a plot of the HR diagram of these sources to reproduce Figure 3 from Burke et al.:
import matplotlib.pyplot as pl
pl.plot(base_stlr.teff, base_stlr.logg, ".k", ms=3, alpha=0.5)
pl.plot(stlr.teff, stlr.logg, ".r", ms=3, alpha=0.5)
pl.xlim(9500, 2500)
pl.ylim(5.5, 3)
pl.ylabel("$\log g$")
pl.xlabel("$T_\mathrm{eff}$");
<>:7: SyntaxWarning: invalid escape sequence '\l'
<>:8: SyntaxWarning: invalid escape sequence '\m'
<>:7: SyntaxWarning: invalid escape sequence '\l'
<>:8: SyntaxWarning: invalid escape sequence '\m'
/tmp/ipykernel_2439/1651322040.py:7: SyntaxWarning: invalid escape sequence '\l'
pl.ylabel("$\log g$")
/tmp/ipykernel_2439/1651322040.py:8: SyntaxWarning: invalid escape sequence '\m'
pl.xlabel("$T_\mathrm{eff}$");
Next up, let’s make the cuts on the KOI list:
- disposition from the Q1-Q16 pipeline run:
CANDIDATE, $50\,\mathrm{day} \le P \le 300\,\mathrm{day}$, and$0.75\,R_\oplus \le R \le 2.5\,R_\oplus$.
kois = get_catalog(
"q1_q16_koi",
columns="kepid,koi_pdisposition,koi_period,koi_prad,koi_prad_err1,koi_prad_err2",
)
period_rng = (50, 300)
rp_rng = (0.75, 2.5)
# Join on the stellar list.
kois = pd.merge(kois, stlr[["kepid"]], on="kepid", how="inner")
# Only select the KOIs in the relevant part of parameter space.
m = kois.koi_pdisposition == "CANDIDATE"
m &= np.isfinite(kois.koi_period)
m &= np.isfinite(kois.koi_prad)
base_kois = pd.DataFrame(kois[m])
m &= (period_rng[0] <= kois.koi_period) & (kois.koi_period <= period_rng[1])
m &= (rp_rng[0] <= kois.koi_prad) & (kois.koi_prad <= rp_rng[1])
kois = pd.DataFrame(kois[m])
print("Selected {0} KOIs after cuts".format(len(kois)))
Using cached data file.
Selected 154 KOIs after cuts
Burke et al. find 156 KOIs instead of our 154 again because of their pre-release version of the catalog and changing dispositions. As we’ll see, this doesn’t have a huge effect on the results even though there’s some risk of being dominated by small number statistics.
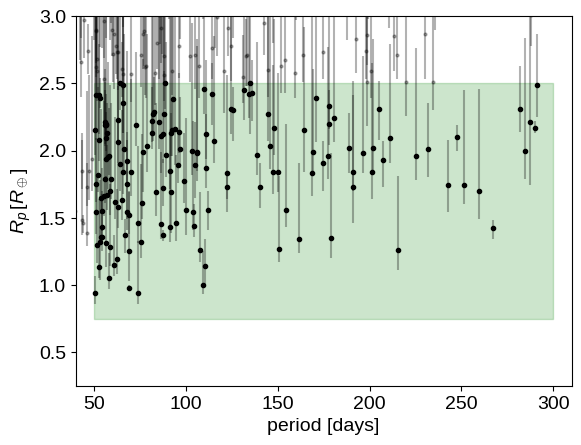
Now, let’s plot the distribution of measured physical parameters in this catalog of KOIs. Unlike most versions of this plot, here we’ll include the error bars on the radii as a reminder that many of the radii are very poorly constrained!
yerr = np.abs(np.array(base_kois[["koi_prad_err2", "koi_prad_err1"]])).T
pl.errorbar(
base_kois.koi_period,
base_kois.koi_prad,
yerr=yerr,
fmt=".k",
ms=4,
capsize=0,
alpha=0.3,
)
pl.plot(kois.koi_period, kois.koi_prad, ".k", ms=6)
pl.fill_between(
period_rng, [rp_rng[1], rp_rng[1]], [rp_rng[0], rp_rng[0]], color="g", alpha=0.2
)
pl.xlim(period_rng + 10 * np.array([-1, 1]))
pl.ylim(rp_rng + 0.5 * np.array([-1, 1]))
pl.xlabel("period [days]")
pl.ylabel("$R_p \, [R_\oplus]$");
<>:18: SyntaxWarning: invalid escape sequence '\,'
<>:18: SyntaxWarning: invalid escape sequence '\,'
/tmp/ipykernel_2439/3333329861.py:18: SyntaxWarning: invalid escape sequence '\,'
pl.ylabel("$R_p \, [R_\oplus]$");
The detection efficiency model#
For this problem of population inference, an important ingredient is a detailed model of the efficiency with which the transit search pipeline detects transit signals. Burke et al. implement an analytic model for the detection efficiency that has been calibrated using simulations in a (submitted but unavailable) paper by Jessie Christiansen. The details of this model are given in the Burke et al. paper so I’ll just go ahead and implement it and if you’re interested, check out the paper.
from scipy.stats import gamma
def get_duration(period, aor, e):
"""
Equation (1) from Burke et al. This estimates the transit
duration in the same units as the input period. There is a
typo in the paper (24/4 = 6 != 4).
:param period: the period in any units of your choosing
:param aor: the dimensionless semi-major axis (scaled
by the stellar radius)
:param e: the eccentricity of the orbit
"""
return 0.25 * period * np.sqrt(1 - e**2) / aor
def get_a(period, mstar, Go4pi=2945.4625385377644 / (4 * np.pi * np.pi)):
"""
Compute the semi-major axis of an orbit in Solar radii.
:param period: the period in days
:param mstar: the stellar mass in Solar masses
"""
return (Go4pi * period * period * mstar) ** (1.0 / 3)
def get_delta(k, c=1.0874, s=1.0187):
"""
Estimate the approximate expected transit depth as a function
of radius ratio. There might be a typo here. In the paper it
uses c + s*k but in the public code, it is c - s*k:
https://github.com/christopherburke/KeplerPORTs
:param k: the dimensionless radius ratio between the planet and
the star
"""
delta_max = k * k * (c + s * k)
return 0.84 * delta_max
cdpp_cols = [k for k in stlr.keys() if k.startswith("rrmscdpp")]
cdpp_vals = np.array([k[-4:].replace("p", ".") for k in cdpp_cols], dtype=float)
def get_mes(star, period, rp, tau, re=0.009171):
"""
Estimate the multiple event statistic value for a transit.
:param star: a pandas row giving the stellar properties
:param period: the period in days
:param rp: the planet radius in Earth radii
:param tau: the transit duration in hours
"""
# Interpolate to the correct CDPP for the duration.
cdpp = np.array(star[cdpp_cols], dtype=float)
sigma = np.interp(tau, cdpp_vals, cdpp)
# Compute the radius ratio and estimate the S/N.
k = rp * re / star.radius
snr = get_delta(k) * 1e6 / sigma
# Scale by the estimated number of transits.
ntrn = star.dataspan * star.dutycycle / period
return snr * np.sqrt(ntrn)
# Pre-compute and freeze the gamma function from Equation (5) in
# Burke et al.
pgam = gamma(4.65, loc=0.0, scale=0.98)
mesthres_cols = [k for k in stlr.keys() if k.startswith("mesthres")]
mesthres_vals = np.array([k[-4:].replace("p", ".") for k in mesthres_cols], dtype=float)
def get_pdet(star, aor, period, rp, e):
"""
Equation (5) from Burke et al. Estimate the detection efficiency
for a transit.
:param star: a pandas row giving the stellar properties
:param aor: the dimensionless semi-major axis (scaled
by the stellar radius)
:param period: the period in days
:param rp: the planet radius in Earth radii
:param e: the orbital eccentricity
"""
tau = get_duration(period, aor, e) * 24.0
mes = get_mes(star, period, rp, tau)
mest = np.interp(tau, mesthres_vals, np.array(star[mesthres_cols], dtype=float))
x = mes - 4.1 - (mest - 7.1)
return pgam.cdf(x)
def get_pwin(star, period):
"""
Equation (6) from Burke et al. Estimates the window function
using a binomial distribution.
:param star: a pandas row giving the stellar properties
:param period: the period in days
"""
M = star.dataspan / period
f = star.dutycycle
omf = 1.0 - f
pw = (
1
- omf**M
- M * f * omf ** (M - 1)
- 0.5 * M * (M - 1) * f * f * omf ** (M - 2)
)
msk = (pw >= 0.0) * (M >= 2.0)
return pw * msk
def get_pgeom(aor, e):
"""
The geometric transit probability.
See e.g. Kipping (2014) for the eccentricity factor
http://arxiv.org/abs/1408.1393
:param aor: the dimensionless semi-major axis (scaled
by the stellar radius)
:param e: the orbital eccentricity
"""
return 1.0 / (aor * (1 - e * e)) * (aor > 1.0)
def get_completeness(star, period, rp, e, with_geom=True):
"""
A helper function to combine all the completeness effects.
:param star: a pandas row giving the stellar properties
:param period: the period in days
:param rp: the planet radius in Earth radii
:param e: the orbital eccentricity
:param with_geom: include the geometric transit probability?
"""
aor = get_a(period, star.mass) / star.radius
pdet = get_pdet(star, aor, period, rp, e)
pwin = get_pwin(star, period)
if not with_geom:
return pdet * pwin
pgeom = get_pgeom(aor, e)
return pdet * pwin * pgeom
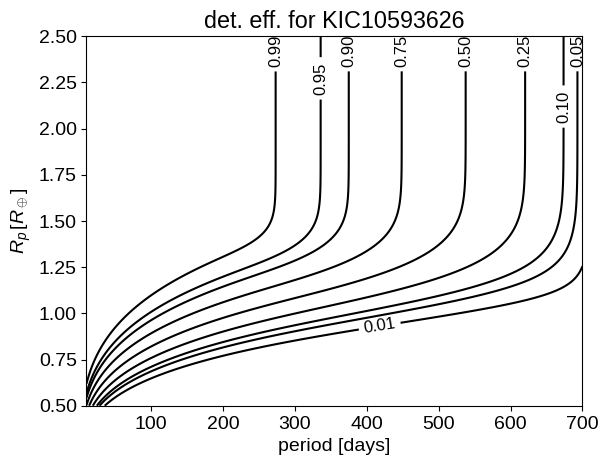
Using this model, lets reproduce Figure 1 from the Burke paper. If you closely compare the figures, you’ll find that they’re not quite the same but the one in the paper was generated with an older (incomplete) version of the code (Burke, priv. comm.) and the model used is actually the same as this one so we’ll roll with it!
# Choose the star.
star = stlr[stlr.kepid == 10593626].iloc[0]
# Compute the completeness map on a grid.
period = np.linspace(10, 700, 500)
rp = np.linspace(0.5, 2.5, 421)
X, Y = np.meshgrid(period, rp, indexing="ij")
Z = get_completeness(star, X, Y, 0.0, with_geom=False)
# Plot with the same contour levels as the figure.
c = pl.contour(X, Y, Z, [0.01, 0.05, 0.1, 0.25, 0.5, 0.75, 0.9, 0.95, 0.99], colors="k")
pl.clabel(c, fontsize=12, inline=1, fmt="%.2f")
pl.xlabel("period [days]")
pl.ylabel("$R_p \, [R_\oplus]$")
pl.title("det. eff. for KIC10593626");
<>:14: SyntaxWarning: invalid escape sequence '\,'
<>:14: SyntaxWarning: invalid escape sequence '\,'
/tmp/ipykernel_2439/2038380559.py:14: SyntaxWarning: invalid escape sequence '\,'
pl.ylabel("$R_p \, [R_\oplus]$")
In practice, the only detection efficiency function that enters our analysis is integrated across the stellar sample. In fact, the function $Q(w)$ needs to be integrated (marginalized) over all the parameters that affect it but aren’t of interest, for example, we should include eccentricity. For now, following Burke et al., we’ll ignore eccentricity and integrate only over the stellar parameters. This cell takes a minute or two to run because it must loop over every star in the sample and compute the completeness on a grid.
period = np.linspace(period_rng[0], period_rng[1], 57)
rp = np.linspace(rp_rng[0], rp_rng[1], 61)
period_grid, rp_grid = np.meshgrid(period, rp, indexing="ij")
comp = np.zeros_like(period_grid)
for _, star in stlr.iterrows():
comp += get_completeness(star, period_grid, rp_grid, 0.0, with_geom=True)
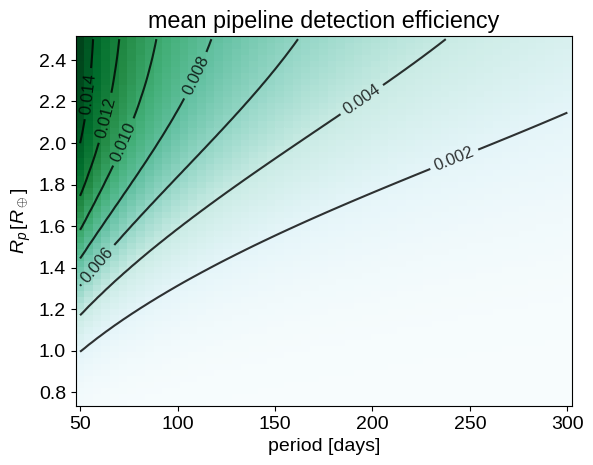
In the target range, here is the completeness function (including the geometric transit probability):
pl.pcolor(period_grid, rp_grid, comp, cmap="BuGn")
c = pl.contour(period_grid, rp_grid, comp / len(stlr), colors="k", alpha=0.8)
pl.clabel(c, fontsize=12, inline=1, fmt="%.3f")
pl.title("mean pipeline detection efficiency")
pl.xlabel("period [days]")
pl.ylabel("$R_p \, [R_\oplus]$");
<>:6: SyntaxWarning: invalid escape sequence '\,'
<>:6: SyntaxWarning: invalid escape sequence '\,'
/tmp/ipykernel_2439/993405964.py:6: SyntaxWarning: invalid escape sequence '\,'
pl.ylabel("$R_p \, [R_\oplus]$");
Population inference#
Now that we have our sample and our completeness model, we need to specify the underlying population model. Like Burke et al., I’ve found that the data don’t support a broken power law in planet radius so let’s just model the population as the product of indpendent power laws in $P$ and $R_p$.
# A double power law model for the population.
def population_model(theta, period, rp):
lnf0, beta, alpha = theta
v = np.exp(lnf0) * np.ones_like(period)
for x, rng, n in zip((period, rp), (period_rng, rp_rng), (beta, alpha)):
n1 = n + 1
v *= x**n * n1 / (rng[1] ** n1 - rng[0] ** n1)
return v
# The ln-likelihood function given at the top of this post.
koi_periods = np.array(kois.koi_period)
koi_rps = np.array(kois.koi_prad)
vol = np.diff(period_grid, axis=0)[:, :-1] * np.diff(rp_grid, axis=1)[:-1, :]
def lnlike(theta):
pop = population_model(theta, period_grid, rp_grid) * comp
pop = 0.5 * (pop[:-1, :-1] + pop[1:, 1:])
norm = np.sum(pop * vol)
ll = np.sum(np.log(population_model(theta, koi_periods, koi_rps))) - norm
return ll if np.isfinite(ll) else -np.inf
# The ln-probability function is just propotional to the ln-likelihood
# since we're assuming uniform priors.
bounds = [(-5, 5), (-5, 5), (-5, 5)]
def lnprob(theta):
# Broad uniform priors.
for t, rng in zip(theta, bounds):
if not rng[0] < t < rng[1]:
return -np.inf
return lnlike(theta)
# The negative ln-likelihood is useful for optimization.
# Optimizers want to *minimize* your function.
def nll(theta):
ll = lnlike(theta)
return -ll if np.isfinite(ll) else 1e15
To start, let’s find the maximum likelihood solution for the population parameters by minimizing the negative log-likelihood.
from scipy.optimize import minimize
theta_0 = np.array([np.log(0.75), -0.53218, -1.5])
r = minimize(nll, theta_0, method="L-BFGS-B", bounds=bounds)
print(r)
message: CONVERGENCE: RELATIVE REDUCTION OF F <= FACTR*EPSMCH
success: True
status: 0
fun: 1162.5264684357792
x: [-4.101e-01 -5.799e-01 -1.233e+00]
nit: 8
jac: [ 2.274e-05 2.274e-05 0.000e+00]
nfev: 44
njev: 11
hess_inv: <3x3 LbfgsInvHessProduct with dtype=float64>
…and plot it:
# We'll reuse these functions to plot all of our results.
def make_plot(pop_comp, x0, x, y, ax):
pop = 0.5 * (pop_comp[:, 1:] + pop_comp[:, :-1])
pop = np.sum(pop * np.diff(y)[None, :, None], axis=1)
a, b, c, d, e = np.percentile(pop * np.diff(x)[0], [2.5, 16, 50, 84, 97.5], axis=0)
ax.fill_between(x0, a, e, color="k", alpha=0.1, edgecolor="none")
ax.fill_between(x0, b, d, color="k", alpha=0.3, edgecolor="none")
ax.plot(x0, c, "k", lw=1)
def plot_results(samples):
# Loop through the samples and compute the list of population models.
samples = np.atleast_2d(samples)
pop = np.empty((len(samples), period_grid.shape[0], period_grid.shape[1]))
gamma_earth = np.empty((len(samples)))
for i, p in enumerate(samples):
pop[i] = population_model(p, period_grid, rp_grid)
gamma_earth[i] = population_model(p, 365.25, 1.0) * 365.0
fig, axes = pl.subplots(2, 2, figsize=(10, 8))
fig.subplots_adjust(wspace=0.4, hspace=0.4)
# Integrate over period.
dx = 0.25
x = np.arange(rp_rng[0], rp_rng[1] + dx, dx)
n, _ = np.histogram(koi_rps, x)
# Plot the observed radius distribution.
ax = axes[0, 0]
make_plot(pop * comp[None, :, :], rp, x, period, ax)
ax.errorbar(0.5 * (x[:-1] + x[1:]), n, yerr=np.sqrt(n), fmt=".k", capsize=0)
ax.set_xlim(rp_rng[0], rp_rng[1])
ax.set_xlabel("$R_p\,[R_\oplus]$")
ax.set_ylabel("\# of detected planets")
# Plot the true radius distribution.
ax = axes[0, 1]
make_plot(pop, rp, x, period, ax)
ax.set_xlim(rp_rng[0], rp_rng[1])
ax.set_ylim(0, 0.37)
ax.set_xlabel("$R_p\,[R_\oplus]$")
ax.set_ylabel("$\mathrm{d}N / \mathrm{d}R$; $\Delta R = 0.25\,R_\oplus$")
# Integrate over period.
dx = 31.25
x = np.arange(period_rng[0], period_rng[1] + dx, dx)
n, _ = np.histogram(koi_periods, x)
# Plot the observed period distribution.
ax = axes[1, 0]
make_plot(np.swapaxes(pop * comp[None, :, :], 1, 2), period, x, rp, ax)
ax.errorbar(0.5 * (x[:-1] + x[1:]), n, yerr=np.sqrt(n), fmt=".k", capsize=0)
ax.set_xlim(period_rng[0], period_rng[1])
ax.set_ylim(0, 79)
ax.set_xlabel("$P\,[\mathrm{days}]$")
ax.set_ylabel("\# of detected planets")
# Plot the true period distribution.
ax = axes[1, 1]
make_plot(np.swapaxes(pop, 1, 2), period, x, rp, ax)
ax.set_xlim(period_rng[0], period_rng[1])
ax.set_ylim(0, 0.27)
ax.set_xlabel("$P\,[\mathrm{days}]$")
ax.set_ylabel("$\mathrm{d}N / \mathrm{d}P$; $\Delta P = 31.25\,\mathrm{days}$")
return gamma_earth
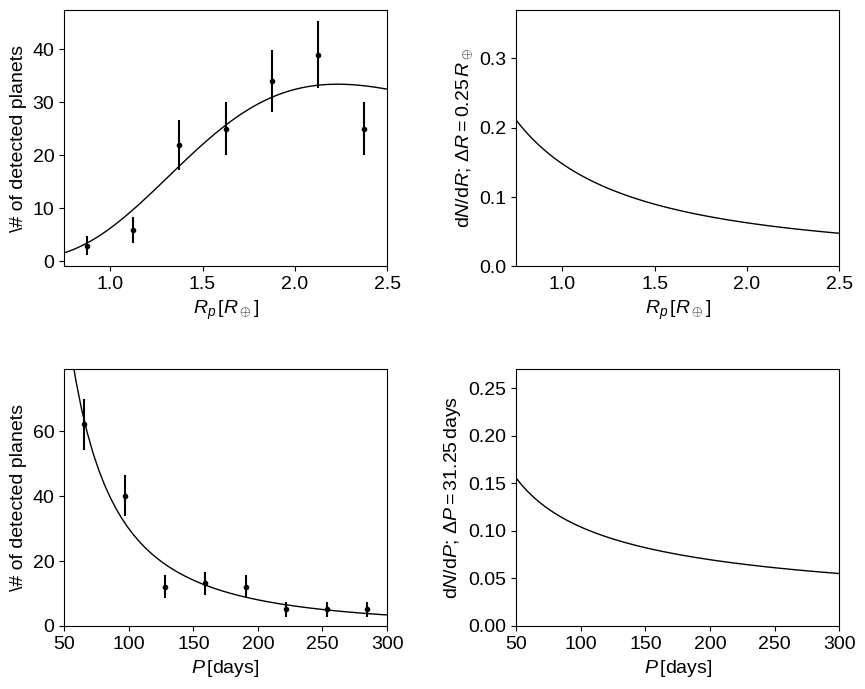
print(plot_results(r.x));
<>:34: SyntaxWarning: invalid escape sequence '\,'
[0.50960663]
<>:35: SyntaxWarning: invalid escape sequence '\#'
<>:42: SyntaxWarning: invalid escape sequence '\,'
<>:43: SyntaxWarning: invalid escape sequence '\m'
<>:56: SyntaxWarning: invalid escape sequence '\,'
<>:57: SyntaxWarning: invalid escape sequence '\#'
<>:64: SyntaxWarning: invalid escape sequence '\,'
<>:65: SyntaxWarning: invalid escape sequence '\m'
<>:34: SyntaxWarning: invalid escape sequence '\,'
<>:35: SyntaxWarning: invalid escape sequence '\#'
<>:42: SyntaxWarning: invalid escape sequence '\,'
<>:43: SyntaxWarning: invalid escape sequence '\m'
<>:56: SyntaxWarning: invalid escape sequence '\,'
<>:57: SyntaxWarning: invalid escape sequence '\#'
<>:64: SyntaxWarning: invalid escape sequence '\,'
<>:65: SyntaxWarning: invalid escape sequence '\m'
/tmp/ipykernel_2439/627950470.py:34: SyntaxWarning: invalid escape sequence '\,'
ax.set_xlabel("$R_p\,[R_\oplus]$")
/tmp/ipykernel_2439/627950470.py:35: SyntaxWarning: invalid escape sequence '\#'
ax.set_ylabel("\# of detected planets")
/tmp/ipykernel_2439/627950470.py:42: SyntaxWarning: invalid escape sequence '\,'
ax.set_xlabel("$R_p\,[R_\oplus]$")
/tmp/ipykernel_2439/627950470.py:43: SyntaxWarning: invalid escape sequence '\m'
ax.set_ylabel("$\mathrm{d}N / \mathrm{d}R$; $\Delta R = 0.25\,R_\oplus$")
/tmp/ipykernel_2439/627950470.py:56: SyntaxWarning: invalid escape sequence '\,'
ax.set_xlabel("$P\,[\mathrm{days}]$")
/tmp/ipykernel_2439/627950470.py:57: SyntaxWarning: invalid escape sequence '\#'
ax.set_ylabel("\# of detected planets")
/tmp/ipykernel_2439/627950470.py:64: SyntaxWarning: invalid escape sequence '\,'
ax.set_xlabel("$P\,[\mathrm{days}]$")
/tmp/ipykernel_2439/627950470.py:65: SyntaxWarning: invalid escape sequence '\m'
ax.set_ylabel("$\mathrm{d}N / \mathrm{d}P$; $\Delta P = 31.25\,\mathrm{days}$")
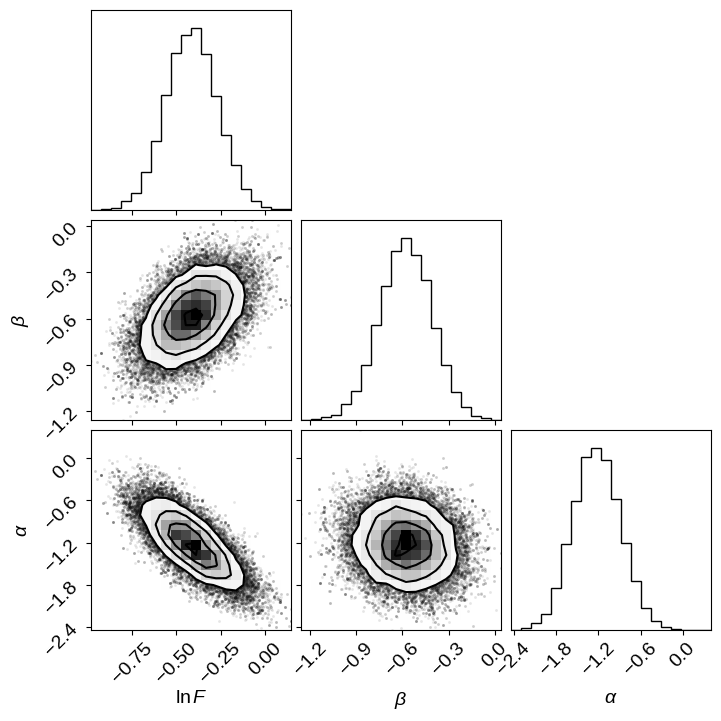
Finally, let’s sample from the posterior probability for the population parameters using emcee.
import emcee
ndim, nwalkers = len(r.x), 16
pos = [r.x + 1e-5 * np.random.randn(ndim) for i in range(nwalkers)]
sampler = emcee.EnsembleSampler(nwalkers, ndim, lnprob)
# Burn in.
pos, _, _ = sampler.run_mcmc(pos, 1000)
sampler.reset()
# Production.
pos, _, _ = sampler.run_mcmc(pos, 4000)
import corner
corner.corner(sampler.flatchain, labels=[r"$\ln F$", r"$\beta$", r"$\alpha$"]);
gamma_earth = plot_results(sampler.flatchain)
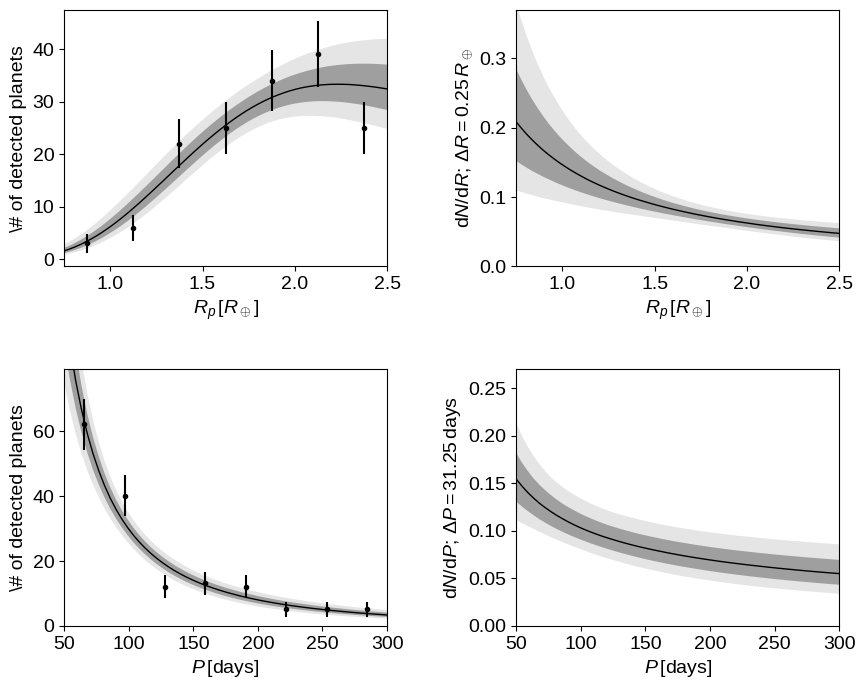
Comparing this to Figures 6–9 in Burke et al., you’ll see that the results are more or less consistent and the predicted observations are good. For radii smaller than $R_\oplus$, the results start to diverge since I chose to use a single power law in radius instead of the double power law. When I tried to use a double power law, I found that the break radius was immediately pushed below $0.95\,R_\oplus$ (the smallest radius in the dataset) and the slope of the smaller radius power law was set only by the prior so it didn’t seem necessary to include it here. In practice the final results are still consistent.
I would now claim this as a successful reproduction of the results from Burke et al. using only public datasets and their description of their method. One last interesting plot (that you might have noticed I computed in the plot_results function) is Figure 17 showing the rate of Earth-analogs defined (following my definition) as:
Let’s plot the constraint on $\Gamma_\oplus$:
pl.hist(np.log10(gamma_earth), 50, histtype="step", color="k")
pl.gca().set_yticklabels([])
pl.title("the rate of Earth analogs")
pl.xlabel(
r"$\log_{10}\Gamma_\oplus = \left. \log_{10}\mathrm{d}N / \mathrm{d}\ln P \, \mathrm{d}\ln R_p \right |_\oplus$"
);
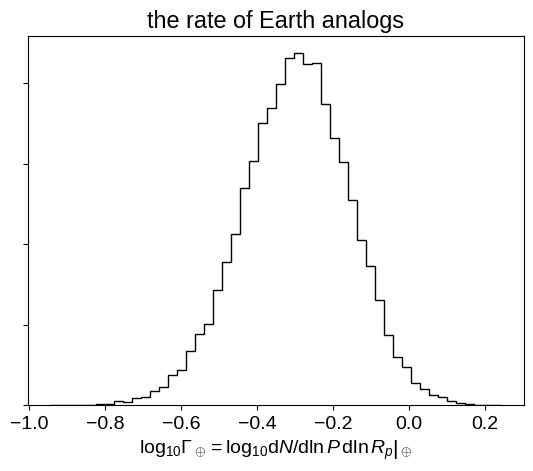
This plot is consistent with Figure 17 from Burke et al. (2015) so we’ll leave it here and call this a success for open science! Some of you might notice that this result is inconsistent with many previous estimates of this number (including my own!) but the discussion of this discrepancy is a topic for another day (or maybe a scientific publication).
Thanks to Ruth Angus for reading through and catching some typos!