Mixture Models
The source for this post can be found here. Please open an issue or pull request on that repository if you have questions, comments, or suggestions.
This post can be cited with the DOI: 10.5281/zenodo.15856
There are a lot of reasons why you might use a mixture model and there is a huge related literature. That being said, there are a few questions that I regularly get so I thought that I would write up the answers.
In astronomy, the most common reason for using a mixture model is to fit data with outliers so that’s the language I’ll use but the results are applicable to any other mixture model. The questions that I’ll try to answer are:
- How do you derive the marginalized likelihood—as popularized by Hogg et al. (2010), I think—and why would you want to?
- How do you work out the mixture membership probabilities (or what is the probability that the point is an outlier) after using this model?
The basic model#
The idea here is that you have some data drawn from the model that you care about and some data points that are outliers—drawn from a different model that you don’t care about! For simplicity, let’s consider a linear model. Everything that I derive here will be applicable to other more complicated models but it is easier to visualize the linear case. Hogg et al. (2010) give a nice treatment of this linear model with slightly different notation but they miss a few useful points in the discussion.
To start, let’s generate some fake data:
import numpy as np
import matplotlib.pyplot as pl
# We'll choose the parameters of our synthetic data.
# The outlier probability will be 80%:
true_frac = 0.8
# The linear model has unit slope and zero intercept:
true_params = [1.0, 0.0]
# The outliers are drawn from a Gaussian with zero mean and unit variance:
true_outliers = [0.0, 1.0]
# For reproducibility, let's set the random number seed and generate the data:
np.random.seed(12)
x = np.sort(np.random.uniform(-2, 2, 15))
yerr = 0.2 * np.ones_like(x)
y = true_params[0] * x + true_params[1] + yerr * np.random.randn(len(x))
# Those points are all drawn from the correct model so let's replace some of
# them with outliers.
m_bkg = np.random.rand(len(x)) > true_frac
y[m_bkg] = true_outliers[0]
y[m_bkg] += np.sqrt(true_outliers[1] + yerr[m_bkg] ** 2) * np.random.randn(sum(m_bkg))
Here’s what these data look like. In this plot, the empty, square points are the true outliers. The purple line is the fit if we don’t account for the fact that there are outliers and just treat all the points equally. Compare this to the correct answer (shown as the black line).
# First, fit the data and find the maximum likelihood model ignoring outliers.
A = np.vander(x, 2)
p = np.linalg.solve(np.dot(A.T, A / yerr[:, None] ** 2), np.dot(A.T, y / yerr**2))
# Then save the *true* line.
x0 = np.linspace(-2.1, 2.1, 200)
y0 = np.dot(np.vander(x0, 2), true_params)
# Plot the data and the truth.
pl.errorbar(x, y, yerr=yerr, fmt=",k", ms=0, capsize=0, lw=1, zorder=999)
pl.scatter(x[m_bkg], y[m_bkg], marker="s", s=22, c="w", edgecolor="k", zorder=1000)
pl.scatter(x[~m_bkg], y[~m_bkg], marker="o", s=22, c="k", zorder=1000)
pl.plot(x0, y0, color="k", lw=1.5)
# Plot the best fit line.
pl.plot(x0, x0 * p[0] + p[1], color="#8d44ad", lw=3, alpha=0.5)
pl.xlabel("$x$")
pl.ylabel("$y$")
pl.ylim(-2.5, 2.5)
pl.xlim(-2.1, 2.1);
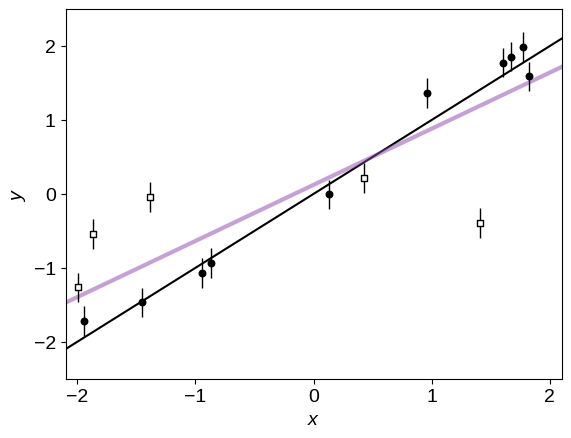
The purple line is clearly a terrible fit because we ignored the outliers. To fix this, let’s generalize this model and add a binary flag $q_k$ for each data point $k$. If $q_k$ is zero, then the point is “good” and the likelihood is given by the usual Gaussian:
where $f_\theta (x_k) = \theta_1 \, x_k + \theta_2$ is the linear model.
Now, if $q_k = 1$ then the point is an outlier and the likelihood becomes:
I have made the simplifying assumption that the outliers are drawn from a single Gaussian with mean $\theta_3$ and variance $\theta_4$. From experience, the results aren’t normally very sensitive to the choice of outlier model and the Gaussian model is often good enough but the following derivations will be valid for any model that you choose.
Under this new model, the full likelihood for the entire dataset becomes:
where, for each term, the correct Gaussian is chosen depending on the value of $q_k$. To write this equation, I’ve assumed that the data points are independent and if that’s not true for your dataset then things get a lot harder.
Now we could just take this likelihood function, apply priors, and use MCMC to find posterior constraints on $\theta$ and the $\{q_k\}$ flags but this would be hard for a few reasons. First, if you’re used to using emcee for your MCMC needs, you’ll find that it’s pretty hard to implement a model with discrete variables so you’d probably need to learn some other sampler and, honestly, it probably wouldn’t work well for this problem either! Which brings us to our second problem. This problem is very high dimensional and the dimension scales with the number of data points. Without the outlier model, the problem is only two-dimensional but when we include the outliers, the model suddenly becomes $(4 + K)$-dimensional, where $K$ is the number of data points. This will always be hard! Therefore, in practice, it is useful to marginalize out the badly behaved parameters ($q_k$) and just sample in $\theta$.
The marginalized likelihood#
In order to marginalize out the $\{q_k\}$ flags, we need to choose a prior $p(q_k)$. After making this choice (I won’t specialize yet), the marginalization can be written:
where the sum is over all the possible permutations of the $q_k$ flags. If you squint for a second, you’ll see that you can actually switch the order of the sum and product without changing anything. This follows from our assumption that the data points are independent. Therefore, we’re left with the much simpler likelihood function
where
The prior $p(q_k)$ could be different for every data point but it is often sufficient to choose a simple model like
where $Q \in [0, 1]$ is a constant that sets the prior probability that a point is drawn from the foreground model. Chosing this model, we recover the (possibly) familiar likelihood function from Hogg et al. (2010):
This is a much easier model to sample so let’s do that now:
import emcee
# Define the probabilistic model...
# A simple prior:
bounds = [(0.1, 1.9), (-0.9, 0.9), (0, 1), (-2.4, 2.4), (-7.2, 5.2)]
def lnprior(p):
# We'll just put reasonable uniform priors on all the parameters.
if not all(b[0] < v < b[1] for v, b in zip(p, bounds)):
return -np.inf
return 0
# The "foreground" linear likelihood:
def lnlike_fg(p):
m, b, _, M, lnV = p
model = m * x + b
return -0.5 * (((model - y) / yerr) ** 2 + 2 * np.log(yerr))
# The "background" outlier likelihood:
def lnlike_bg(p):
_, _, Q, M, lnV = p
var = np.exp(lnV) + yerr**2
return -0.5 * ((M - y) ** 2 / var + np.log(var))
# Full probabilistic model.
def lnprob(p):
m, b, Q, M, lnV = p
# First check the prior.
lp = lnprior(p)
if not np.isfinite(lp):
return -np.inf, np.zeros_like(y), np.zeros_like(y)
# Compute the vector of foreground likelihoods and include the q prior.
ll_fg = lnlike_fg(p)
arg1 = ll_fg + np.log(Q)
# Compute the vector of background likelihoods and include the q prior.
ll_bg = lnlike_bg(p)
arg2 = ll_bg + np.log(1.0 - Q)
# Combine these using log-add-exp for numerical stability.
ll = np.sum(np.logaddexp(arg1, arg2))
# We're using emcee's "blobs" feature in order to keep track of the
# foreground and background likelihoods for reasons that will become
# clear soon.
return lp + ll, arg1, arg2
# Initialize the walkers at a reasonable location.
ndim, nwalkers = 5, 32
p0 = np.array([1.0, 0.0, 0.7, 0.0, np.log(2.0)])
p0 = [p0 + 1e-5 * np.random.randn(ndim) for k in range(nwalkers)]
# Set up the sampler.
sampler = emcee.EnsembleSampler(nwalkers, ndim, lnprob)
# Run a burn-in chain and save the final location.
state = sampler.run_mcmc(p0, 500)
# Run the production chain.
sampler.reset()
sampler.run_mcmc(state, 1500);
This code should only take about a minute to run. Compare that to any attempt you’ve ever made at sampling the same problem with another 15 or more parameters and you should be pretty stoked!
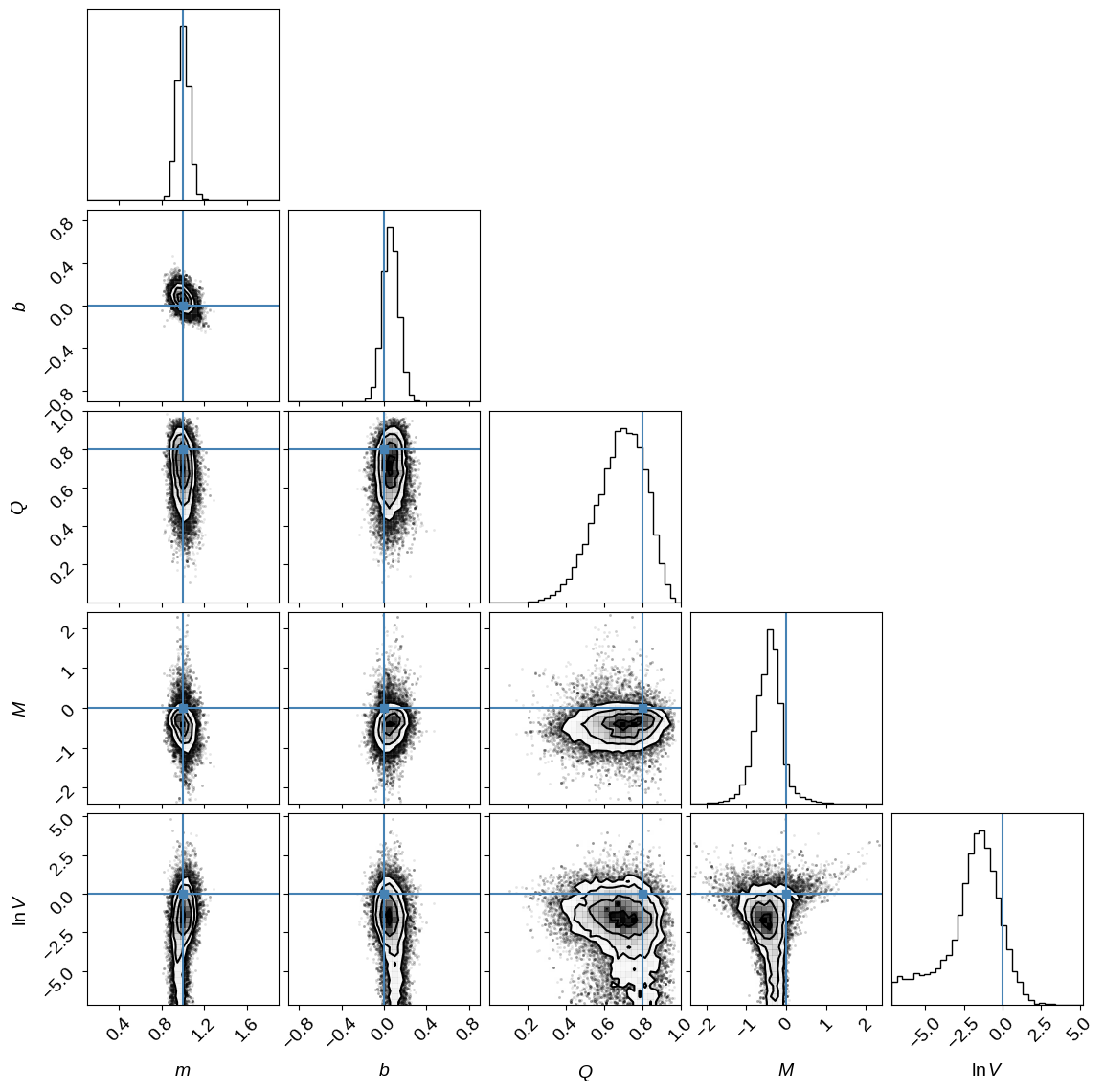
Let’s show the resulting parameter constraints and compare them to the true values (indicated in blue) used to generate the synthetic dataset. This should encourage us that we’ve done something reasonable.
import corner
labels = ["$m$", "$b$", "$Q$", "$M$", "$\ln V$"]
truths = true_params + [true_frac, true_outliers[0], np.log(true_outliers[1])]
corner.corner(sampler.flatchain, bins=35, extents=bounds, labels=labels, truths=truths);
<>:3: SyntaxWarning: invalid escape sequence '\l'
<>:3: SyntaxWarning: invalid escape sequence '\l'
/tmp/ipykernel_2313/3333219463.py:3: SyntaxWarning: invalid escape sequence '\l'
labels = ["$m$", "$b$", "$Q$", "$M$", "$\ln V$"]
WARNING:root:Deprecated keyword argument 'extents'. Use 'range' instead.
Similarly, the predicted constraint on the linear model is:
# Compute the quantiles of the predicted line and plot them.
A = np.vander(x0, 2)
lines = np.dot(sampler.flatchain[:, :2], A.T)
quantiles = np.percentile(lines, [16, 84], axis=0)
pl.fill_between(x0, quantiles[0], quantiles[1], color="#8d44ad", alpha=0.5)
# Plot the data.
pl.errorbar(x, y, yerr=yerr, fmt=",k", ms=0, capsize=0, lw=1, zorder=999)
pl.scatter(x, y, marker="o", s=22, c="k", zorder=1000)
# Plot the true line.
pl.plot(x0, y0, color="k", lw=1.5)
pl.xlabel("$x$")
pl.ylabel("$y$")
pl.ylim(-2.5, 2.5)
pl.xlim(-2.1, 2.1);
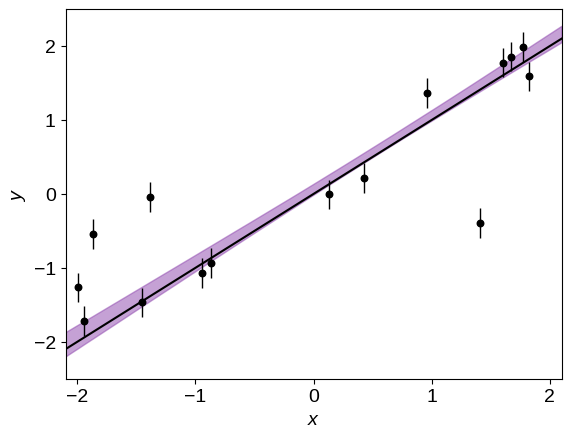
Great! Comparing the purple swath to the true line (shown in black), I think that we can all agree that this is a much better fit! But now, how do we label the points to decide which ones are outliers?
Mixture membership probabilities#
Okay. So now we have a model that we can sample and it seems to give us reasonable results but didn’t we throw away a lot of information when we used the marginalized likelihood instead of sampling in the $q_k$ parameters? If we sampled the full model, we would, after all, get marginalized posterior constraints on the outlierness of each point. This is a very common question when I suggest that people use this model so I wanted to show that you’re actually not throwing anything away and with a tiny bit of extra computation, you can recover these constraints!
To be specific, the thing that we want to compute is:
the posterior probability of a specific point $k$ being good ($q_k=0$) given all the data. In this equation, I’ve simplified the notation a bit and $y = \{y_k\}$ now indicates all the data and I’m leaving out the implied $\{x_k\},\,\{\sigma_k\}$ on the right-hand side of every probability. To compute this, we’ll need to evaluate the conditional probability
where the sum is over every allowed value of $q_k$. Both the numerator and denominator are used when computing the marginalized likelihood so if we hang onto those, we can re-use them to compute the membership probabilities. In the example above, I stored these results using emcee’s blobs feature so it’ll be ease to evaluate $p(q_k\,|\,y,\,\theta^{(n)})$ for each sample $\theta^{(n)}$ from the chain.
Then, we need to realize that the Markov chain gave us samples $\theta^{(n)}$ from the probability distribution $p(\theta\,|\,y)$, so we can approximate the previous integral as
Therefore, the posterior probaility of being an outlier or not can be computed by just taking the average of a bunch of values that we’ve already computed! In practice, this would look like the following:
norm = 0.0
post_prob = np.zeros(len(x))
for i in range(sampler.chain.shape[1]):
for j in range(sampler.chain.shape[0]):
ll_fg, ll_bg = sampler.blobs[i][j]
post_prob += np.exp(ll_fg - np.logaddexp(ll_fg, ll_bg))
norm += 1
post_prob /= norm
Therefore, from left to right, the marginalized posterior probability that each point is part of the foreground model is:
print(", ".join(map("{0:.3f}".format, post_prob)))
0.357, 0.941, 0.000, 0.954, 0.000, 0.888, 0.883, 0.825, 0.852, 0.968, 0.000, 0.994, 0.995, 0.995, 0.976
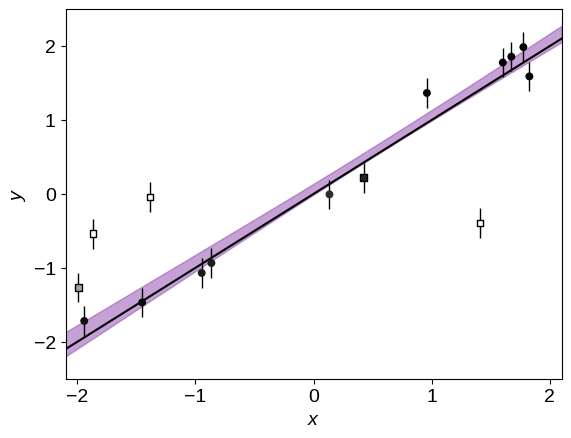
This model works pretty well… so well, in fact, that the strong outliers are given nearly zero probability of being in the foreground model!
Finally, it can be useful to label outliers on the final plot so let’s use a color scale on the points to show this probability. In the figure below, darker points are more likely to be drawn from the line. This plot is pretty satisfying because the model has done a good job labeling all but one outlier at high confidence!
# Plot the predition.
pl.fill_between(x0, quantiles[0], quantiles[1], color="#8d44ad", alpha=0.5)
# Plot the data points.
pl.errorbar(x, y, yerr=yerr, fmt=",k", ms=0, capsize=0, lw=1, zorder=999)
# Plot the (true) outliers.
pl.scatter(
x[m_bkg],
y[m_bkg],
marker="s",
s=22,
c=post_prob[m_bkg],
cmap="gray_r",
edgecolor="k",
vmin=0,
vmax=1,
zorder=1000,
)
# Plot the (true) good points.
pl.scatter(
x[~m_bkg],
y[~m_bkg],
marker="o",
s=22,
c=post_prob[~m_bkg],
cmap="gray_r",
vmin=0,
vmax=1,
zorder=1000,
)
# Plot the true line.
pl.plot(x0, y0, color="k", lw=1.5)
pl.xlabel("$x$")
pl.ylabel("$y$")
pl.ylim(-2.5, 2.5)
pl.xlim(-2.1, 2.1);
Acknowledgments I’d like to thank Ruth Angus for useful comments.